How-I-Landed-My-Data-Analyst-Internship
In the month of April 2022 I was just finishing up my second semester of my Software Development program and with summer coming up I applied to various internship positions. Having previous Data Science experience, I was selected to complete a take-home assignment as part of the interview process for the position of ‘Data Analyst Intern’. This is a record of what the assignment entailed, the questions it asked, and my answers that landed me the position .
_Please note: The dataset provided alongside the assignment states explicitly that the data is completely fictious. _
The dataset contained 830 records each containing 5 columns of data.
The Field Columns were as follows:
| Field | Explanation |
|---|---|
| company_name | The fictitious name of the company inspected. |
| company_food_risk_category | A level of risk associated with the company. |
| inspection_date | The date that the fictitious inspection took place. |
| infraction_weight | The level of severity associated with an infraction. Larger values represent |
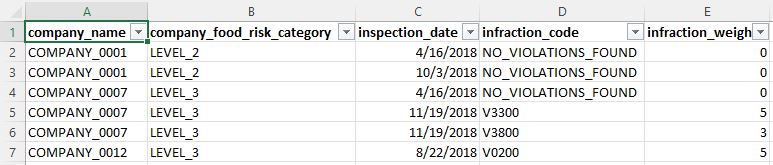
<span class="caption text-muted)Here is a glance at a few rows in the dataset.
Assignment Questions
Question Set 1
There are some data quality issues in the infraction_weight column . Find them and answer the following questions.
- How many did you find?
- What are they?
- Describe in a sentence or two, how you found them.
- Describe in a sentence or two, one possible way to fix the issues you found.
Question Set 2
The infraction_code column uses a placeholder value when an inspector finds no infractions during their inspection. Find them and answer the questions below.
- What is the placeholder they used?
- Describe in a sentence or two, how you determined this.
Question Set 3
The company_food_risk_category column contains a set of values: LEVEL_1, LEVEL_2, LEVEL_3. It is noteworthy that those values are loosely connected to the number of infractions found during inspections and to the severity of each infraction. What other interesting patterns, grouping or trends can you find in the data?
- a. Describe in a sentence or two, one noteworthy or interesting pattern, grouping or trend that you see in the data.
- Describe in a sentence or two, how you discovered that one noteworthy item.
- If you have experience with summarizing data using pivot tables, functions, programming languages (e.g. SQL, R, Python, VBA) or other software packages, choose exactly one output (a screenshot is fine) from your tool of choice to support your noteworthy discovery.
- If you have experience with visualizing data using graphs, charts, infographics, choose exactly one output (a screenshot is fine) from your
Here is my approach and how I answered each question that landed me the position
I received the dataset in .xlsx format so I naturally start by opening it with Microsoft Excel.
I find a good practice when receiving a new dataset is it ‘unhide’ any data that may have been ‘hidden’ by the previous user.
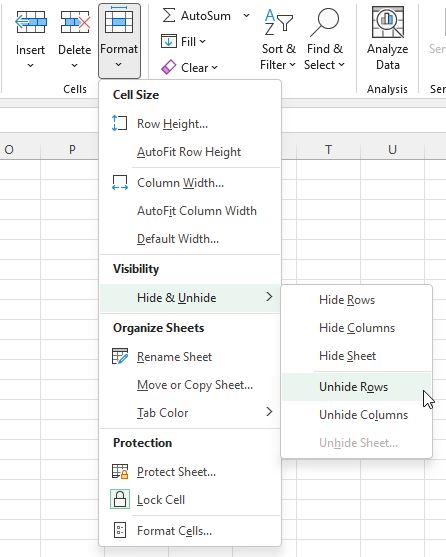 Unhide any hidden rows or columns
Unhide any hidden rows or columns
Another thing I like to do when I am given a dataset is to format the dataset as a table so that I can maintain the integrity of the data.
Once my data is in a format that I can work with I then conduct ‘Exploratory Data Analysis’ which helps me visually see ‘what my data is doing’ and get to know my data a bit better. This also helps with the data cleaning process. I can take my dataset into a program called ‘Open Refine’ and visually see what my data is doing. Here for example, I can see that some numbers are type numerically and some are entered as text.
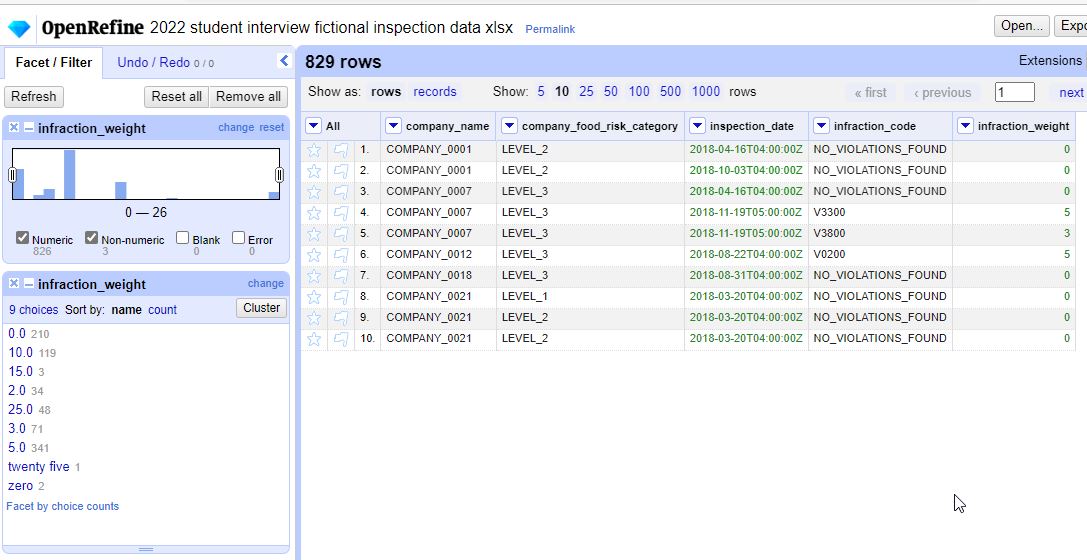 <span class="caption text-muted)OpenRefine allows me to model and clean my data
<span class="caption text-muted)OpenRefine allows me to model and clean my data
I will save my excel file in .csv format so that I can work with it in Python; or more particularly, Jupyter Notebook and conduct some more EDA and Data Cleaning.
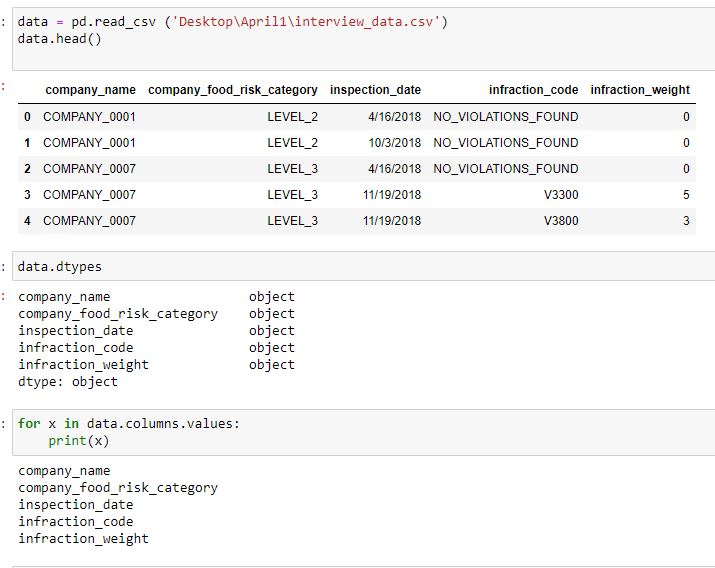
Let's see what the data types are that we are working with
Second I want to see if there are any NaN data types or missing values.
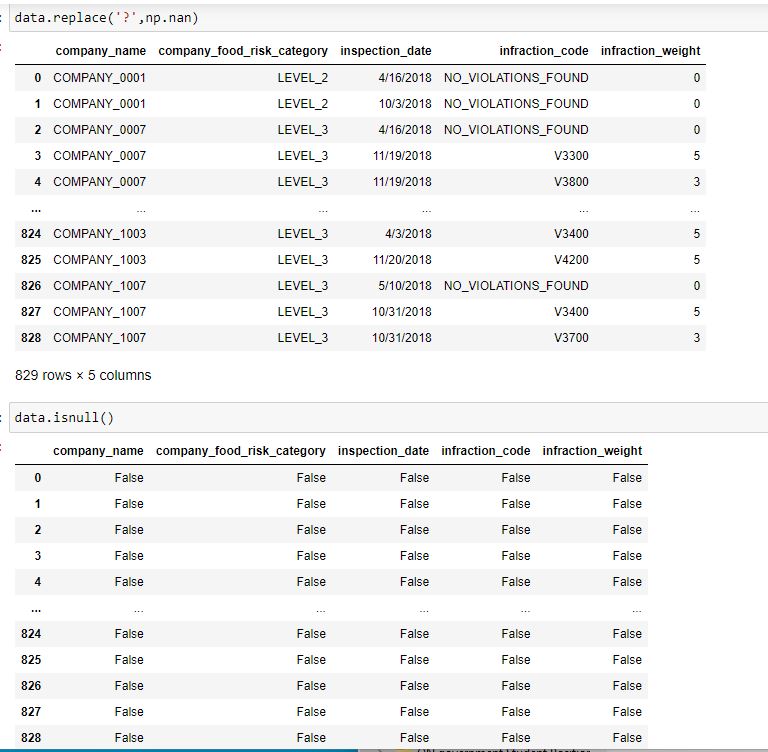
Lastly, I want to see that there is nothing spelled wrong or out of place, that all my ‘unique values’ are what I expect them to be.
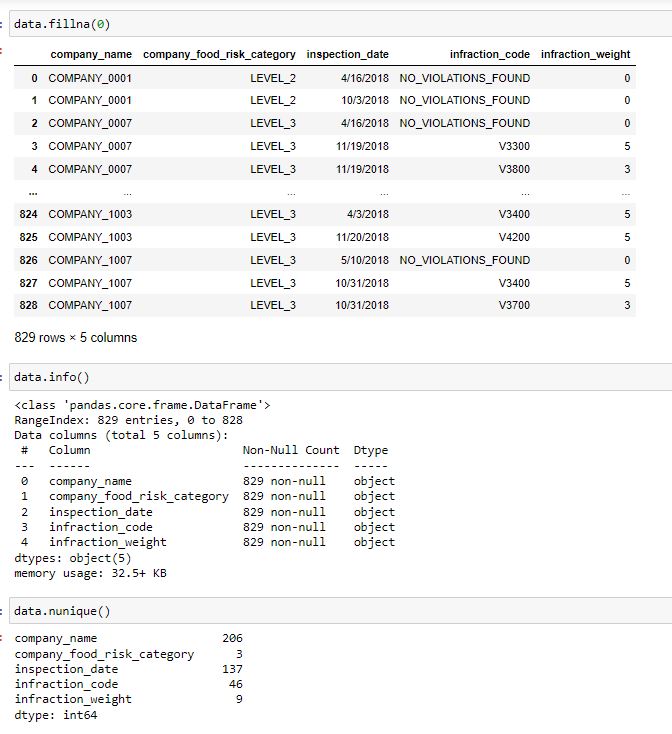 <span class="caption text-muted)I see my data types are 'objects' although I will change them accordingly
<span class="caption text-muted)I see my data types are 'objects' although I will change them accordingly
Now let's answer those questions
Question Set 1 (Answers)
1. I found three instances of inconsistent input of the data in this column

2. While the data type is mostly numeric there are three cells that are written in-text: ‘zero’ ‘zero’ ‘twenty five’.
3. Using OpenRefine, I sorted through the data looking for unclean data. The software allows me to sort by ‘data types’ and while I would expect numeric data in the ‘infraction_weight’ column I can see there are outliers of an inconsistent data type; string and text.
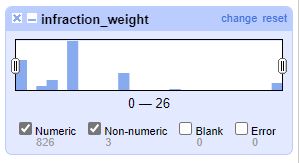
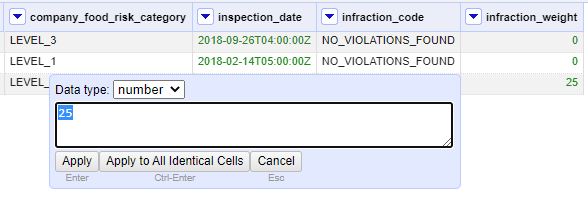
4. OpenRefine allows me to configure each problematic cell by replacing the text data with the numeric data while also changing the data type to ‘numeric’.
Question Set 2 (Answers)
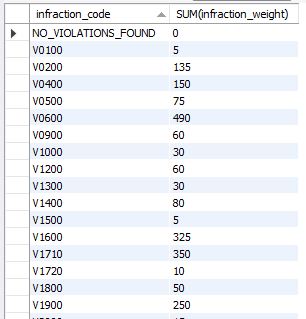
1. The placeholder used when an inspector found no infraction is inputted as 'NO_VIOLATIONS_FOUND'
2.By examination I've simply extrapolated that the corresponding column ‘infraction_weight’ unanimously show that there is zero infraction weight in every instance that no violation was found. Using SQL I can run a query to visually see how many instances an input of ‘NO_VIOLATIONS_FOUND’ corresponded with an infraction weight of any number other than zero and there isn’t a single instance, nor is there a single instance of any other infraction code corresponding with an infraction weight of zero.

Question Set 3 (Answers)
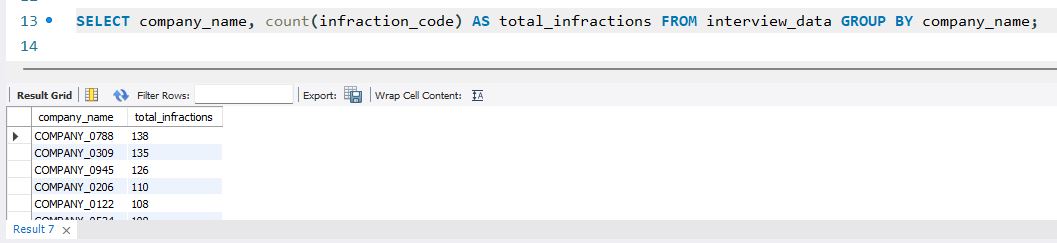
1. I wanted to find out which companies were responsible for the bulk of the violations but also factor in the weight of the violations as well to see who the biggest violators were. I found the following companies to be the top 5 violators in the data:
- Company_0788
- Company_0309
- Company_0945
- Company_0206
- Company_0122
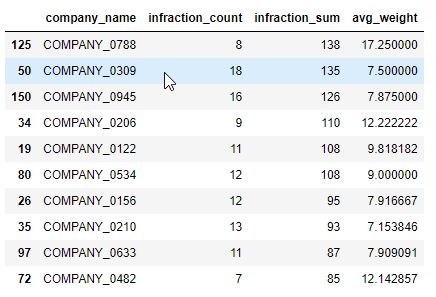
2. Using Python’s ‘pandas’ library I created a new feature that was a simple average of the infraction weight incurred by each company, found by summing the infraction weights and dividing by that specific company’s infraction count. It was found that some companies might have had many infractions, but an overall lower infraction weight, while others had many infractions, weighing higher.
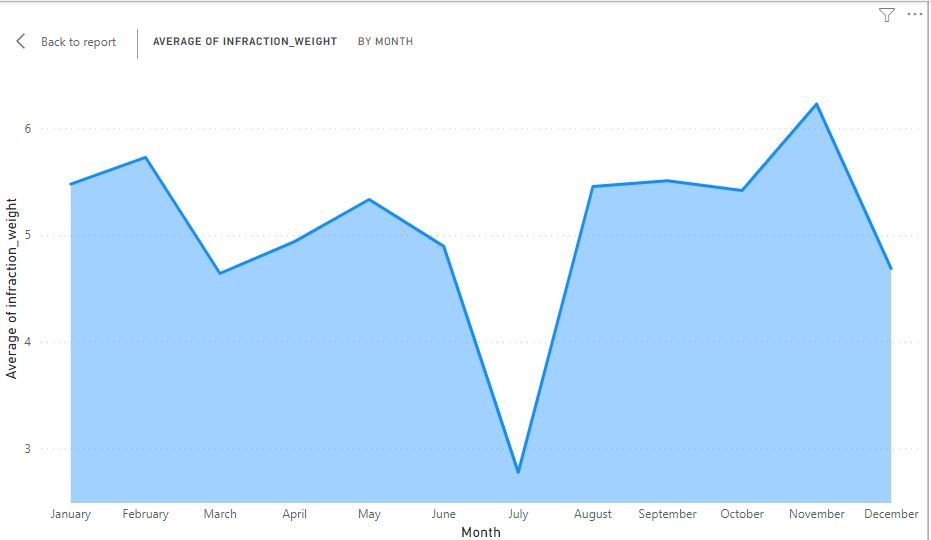
3. Using Power B.I.: I can see that the average weight of infractions drops to its lowest in the month of July. This was done by plotting the infraction weight averages within each month in the year of 2018 found in the dataset.
-End- Thank you for your time.